
RipTide (More Details)
Control-Flow Paradigm and ISA
RipTide employs a steering-based control-flow paradigm (Φ-1) that saves energy. Other mechanisms to implement control-flow include predication and selection (Φ). However, predication can waste energy by frequent masking operations and selection wastes energy by perform both true and false sides of a branch before proceding.
Steering-based control-flow minimizes energy because values operations are gated and performed only when it is determined which side to execute (true and false). Values are then only sent where they are actually needed. These operators (and others) are described in detail in the figures below.
Steering is implemented with the steer operators (in true and false flavors) and the carry operator.
Additionally, RipTide’s ISA includes arithmetic, memory, synchonization, and other operators (see table below).
RipTide’s Full ISA: 
RipTide’s Control-Flow Operators: 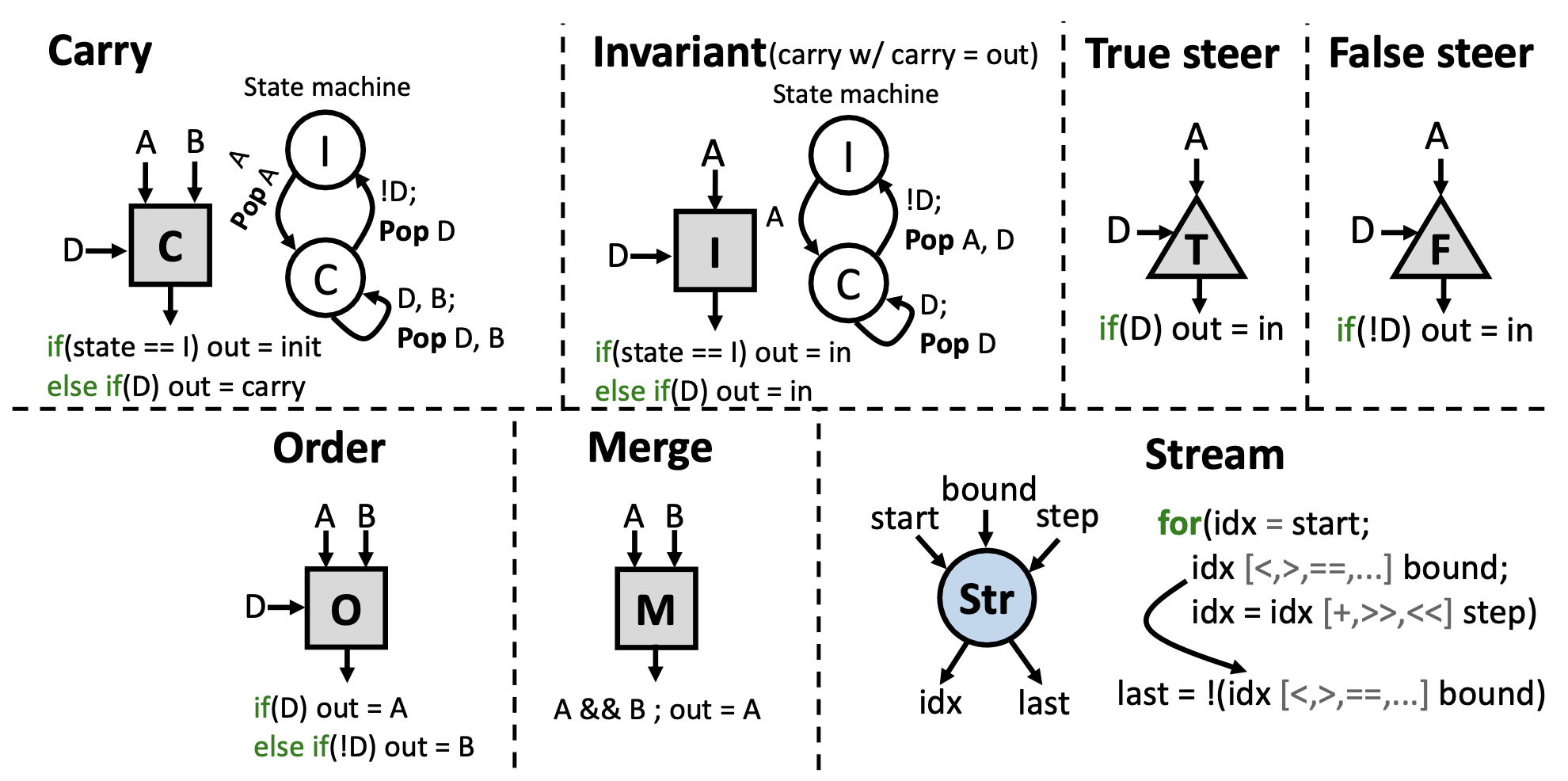
LLVM Compilation Pipeline
RipTide’s compiler (the frontend and middle-end) are implemented in LLVM 12.0.0. It takes lightly annotated C code (no custom annotations), implements RipTide’s control-flow paradigm and memory ordering in LLVM IR, synthesizes the IR into a DFG, and optimizes the DFG.

Streams
RipTide’s compiler identifies affine loop-governing induction variables (LGIVs) in LLVM IR and tracks them into the dataflow graph (DFG) representation. At this level, the subgraph of operators that represent the LGIV in the DFG are fused into a stream operator, which performs an LGIV’s functionality in a single operator and fires a new value every cycle at runtime. See the “Optimized Dataflow Graph” in the compiler pipeline diagram above.
Memory Ordering
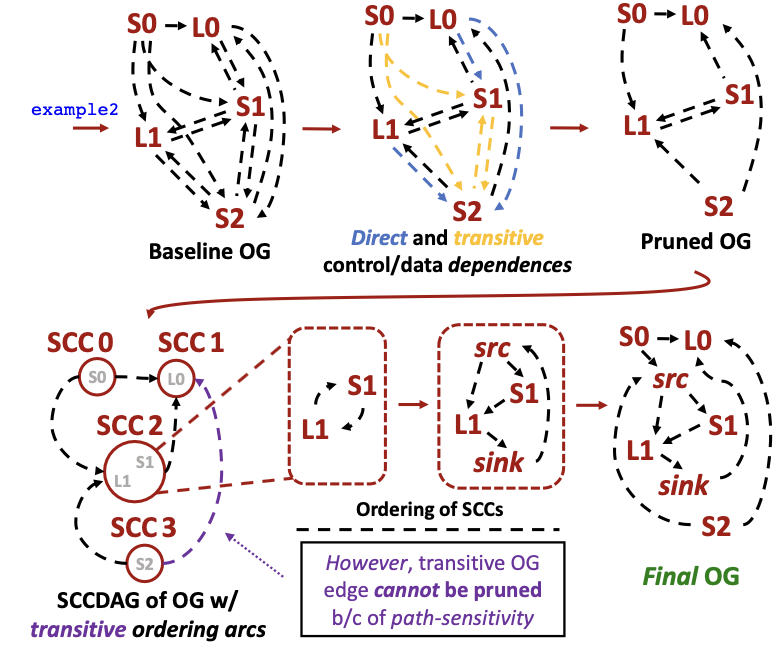
To preserve correctness during dynamic dataflow execution on RipTide’s CGRA fabric, RipTide’s compiler enforces ordering between memory operations. We present an ordering graph abstraction (OG) that encodes may- and must-alias relations between memory operations, derived from alias analysis. Each edge, which represents such relation, must be enforced by the CGRA to ensure correct execution.
We then optimize the OG by removing redundant ordering edges based on existing data- and control-dependences. Finally, we introduce a path-sensitive transitive reduction that performs a reduction of the ordering graph, removing any remaining ordering edges while maintaining correctness with respect to the control-flow present in the original code.
This process can be seen in the diagram below (refers to exmamples code from the compiler diagram above).
Microarchitecture
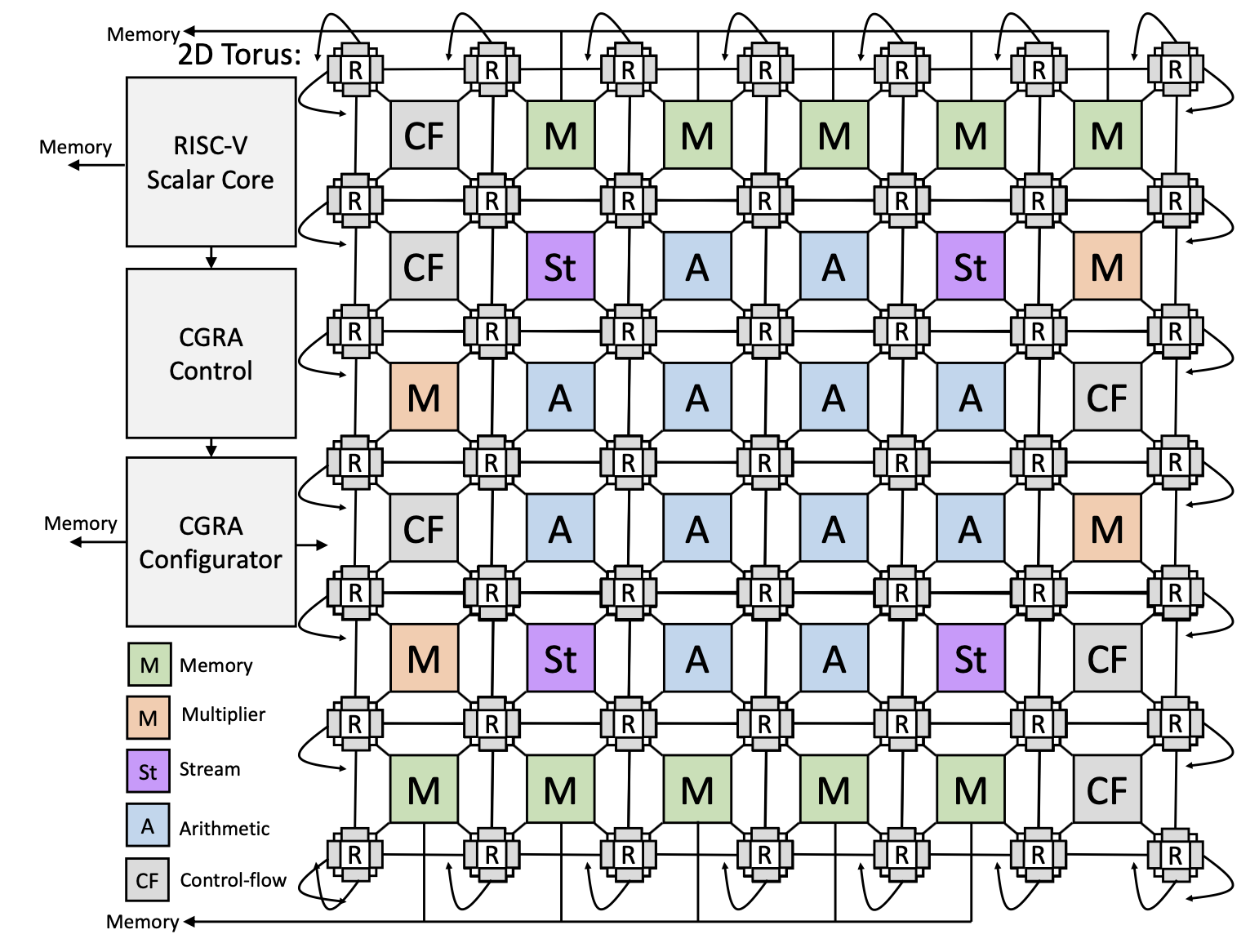
RipTide presents a 6×6 fabric containing heterogeneous PEs connected via a bufferless, 2D-torus NoC. A complete RipTide system contains a CGRA fabric, a RISCV scalar core, and a 256KB (8×32KB banks) SRAM main memory.
Running a DNN on RipTide
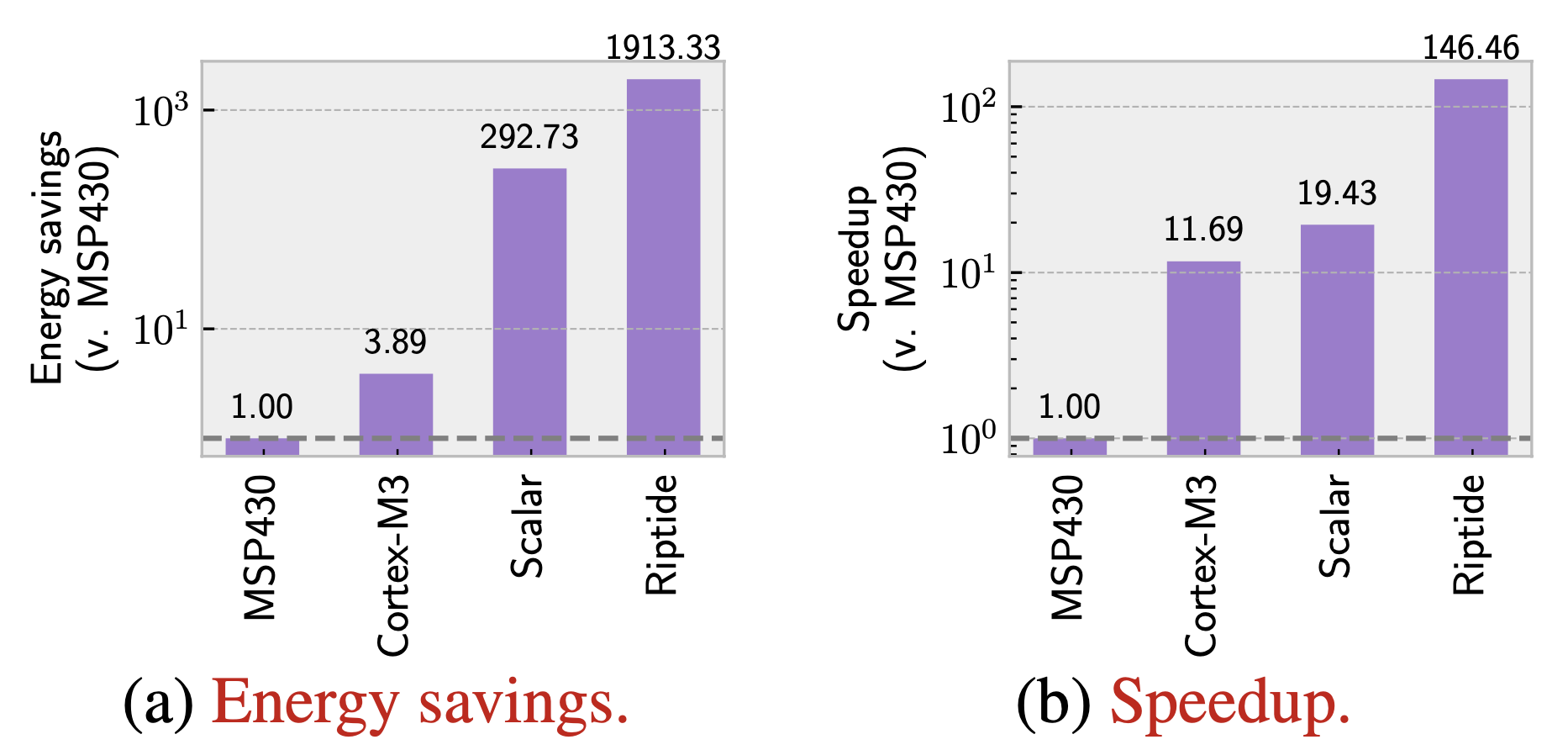
We ran an end-to-end application, DNN inference, on RipTide. The DNN we chose has four layers: two convolution layers separated into three sublayers followed by two fully-connected layers. Every single layer is offloaded to RipTide’s fabric, including convolution, fully- connected, activation, pooling, and normalization layers. Some results can be seen below.
Link
